Posts recientes en el blog http://blog.decisionesinteligentes.com
Por cierto los invito al Webinar sobre Ruby on Rails organizado por @JoeDayz, este próximo 8 de febrero del 4pm a 6pm PST. Se pueden registrar en la pagina de JoeDayz.domingo, febrero 06, 2011
domingo, enero 23, 2011
jueves, diciembre 30, 2010
miércoles, diciembre 08, 2010
EmpleosTI
![]()
El día de hoy anuncio un sitio para publicar ofertas de trabajo relacionadas con Tecnologías de Información, el sitio es empleosTI.
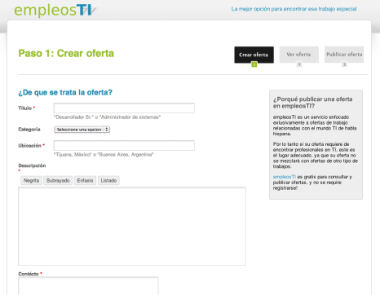
El sitio es muy sencillo de utilizar, no requiere de registro ni para publicar ofertas ni para consultarlas, las ofertan publicadas son enviadas automáticamente a Twitter a través de la cuenta @empleosti_dein, además de tener la posibilidad desde la vista de una oferta de enviarla por email, a Twitter o a Facebook.
Para ver el funcionamiento del sitio les dejo el siguiente video:
Actualmente el sitio aún esta en fase beta, es "usable" y funcional, y no tiene costo para publicar ofertas, así que si están buscando personal de TI.
El sitio salió como idea después de la VAN que di a @altnethispano sobre Ruby on Rails, inicialmente como una aplicación de concepto, después de verlo funcionar decidí hacerlo público como un servicio.
sábado, diciembre 04, 2010
lunes, noviembre 29, 2010
Separación del blog
Durante este pasado fin de semana ha habido una separación del blog, esto a implicado la creación de un nuevo blog en http://blog.decisionesinteligentes.com, donde ya he copiado todos los posts referentes a Ruby y Ruby On Rails, el blog original http://mario-chavez.blogspot.com seguira pero con contenido, quizas, un poco mas personal.
El feed RSS del nuevo blog es http://feeds.feedburner.com/DecisionesInteligentes y la cuenta de twitter queda como @decisionesin
jueves, noviembre 18, 2010
Wash, DRY and fold
DRY es una de las recomendaciones mas mencionadas en el desarrollo de software, DRY es el acronimo de "Don't Repeat Yourself" o "No te repitas" en español.
DRY lo que promueve es la no duplicidad de código fuente en nuestro software, ya que la duplicidad acarrea una serie de problemas de mantenimiento, inconsistencia en la funcionalidad, falta de claridad, etc.
Es por eso que en nuestros desarrollos debemos de buscar patrones de código que se repiten una y otra vez para tratar de extraerlos, abstraerlos y reutilizarlos.
El origen de este post es precisamente, que en un desarrollo en Ruby On Rails que estoy haciendo, encontre estos patrones repetitivos en mis controladores. La mayoría de ellos trabajan haciendo CRUD de manera muy tradicional, por lo tanto las acciones de: Index, Show, Edit, New, Create, Update y Destroy tienen código muy similar a excepción de las referencias al modelo sobre el cual actúan.
Buscando una solución para eliminar esto, me encontré con el proyecto de José Valim (@josevalim) Inherited Resources, el cual trata precisamente sobre como mantenerse DRY.
Algo importante es que Inherited Resources no cambia nuestra forma de trabajar al nombrar variables con nombres genéricos para que puedan ser usadas en nuestros controladores, el se encarga de nombrar las variables de acuerdo a la convención de Rails por lo tanto su uso es bastante transparente.
El post no se trata sobre Inherited Resources, por lo que aqui les dejo ligas a material de referencia para quien guste conocer mas:
¿Bueno entonces de que se trata el post? Es sobre DRY, pero mi implementación de DRY para un problema particular.
En el proyecto que estoy trabajando, tuve la necesidad de que la aplicación de Rails consumiera datos de un API de otra aplicación, la aplicación, de hecho son varias aplicaciones, que contiene lo datos no tiene API, por lo que con una aplicación de Sinatra, le cree un API Rest para que pueda ser consumida con la aplicación Rails - la aplicación de Rails y las aplicaciones sin API están en diferentes servidores/redes -. Esta API Rest puede ser consumida desde Rails a través del uso de ActiveResources, que aparentan ser modelos normales de Rails, pero que en realidad hacen llamados remotos a través de http para obtener sus datos.
En mi problema, tengo un controlador con diversas acciones, donde cada acción hace una llamada Rest a diferentes modelos y muestra los datos obtenidos, hay llamadas que traen una colección de objetos y otras que solamente traen un objeto en particular.
El patron que comencé a ver en las diversas llamadas para traer colecciones de datos fue:
así como la variación siguiente, también para traer colecciones de objetos:
La diferencia entre ellos es que en ocasiones se pasa el ID y en otras no, fuera de eso son muy similares.
Por otro lado, al traer un solo elemento el patrón era el siguiente:
Donde se pasa el ID en otro orden como parametro y la llamada ya no es al metodo all, es a find.
Este código se repetia una y otra ves en mi controlador donde solo cambiaba el nombre del Modelo, así como las variables @modelos y @modelo que es a donde se asignan los datos una vez que se obtienen.
Mi intención aquí es hacer que esto funcione DRY, y con la ayuda de un poco de metaprogramacion es fácil el lograrlo.
La idea es que pudiese hacer algo como:
fetch_resources! :modelo
o
fetch_resource! :modelo
Para obtener mis datos a través de Rest para el modelo adecuado y que se cargara la variable correspondiente con los datos correctos.
Así es como llegue al código que se muestra arriba. El método en singular trae un solo modelo a través de Rest y el metodo en plural trae una colección de modelos, opcionalmente ambos pueden aceptar un filtro en forma de Hash, y el modelo se indica a través de un símbolo.
El metodo fetch! es el que hace toda la magia, primero crea un Hash con el filtro default para todas las llamadas Rest, luego evalúa si a traves de fetch_resource! o fetch_resources! le estamos pasando filtros adicionales, si es así, los integra al Hash de filtro default.
En este punto es donde esta lo mas interesante, usamos en simbolo que se almacena en la variable resource para obtener la referencia a la clase del modelo sobre el cual nos interesa hacer la consulta, por ejemplo si nuestro símbolo es :cliente, asume que tenemos un modelo Cliente y sobre el queremos enviar nuestra solicitud Rest.
Acto seguido identificamos si tenemos un ID a traves del Hash params en el controlador, si es así, identificamos si debemos de llamar al metodo find o all y colocamos los parámetros de la forma correcta, mediante send hacemos el llamado de forma dinamica y el resultado lo guardamos en la variable values.
Finalmente fetch! asume que si tenemos una colección y nuestro símbolo es :cliente, esperamos tener una variable @clientes con los datos, en cambio si tenemos un solo modelo como respuesta y nuestro símbolo sigue siendo :cliente, asume que esperamos una variable @cliente con el dato.
De esta forma en nuestras vistas podemos hacer uso de @clientes o @cliente según corresponda.
Si bien no hubo un ahorro significativo en lineas de código, si hubo la eliminación de lineas de código repetidas y susceptibles a errores o cambios, las cuales fueron reemplazadas por otras instrucciones mas simples que manejan el mismo escenario para cualquiera de mis modelos.
Suscribirse a:
Entradas (Atom)